



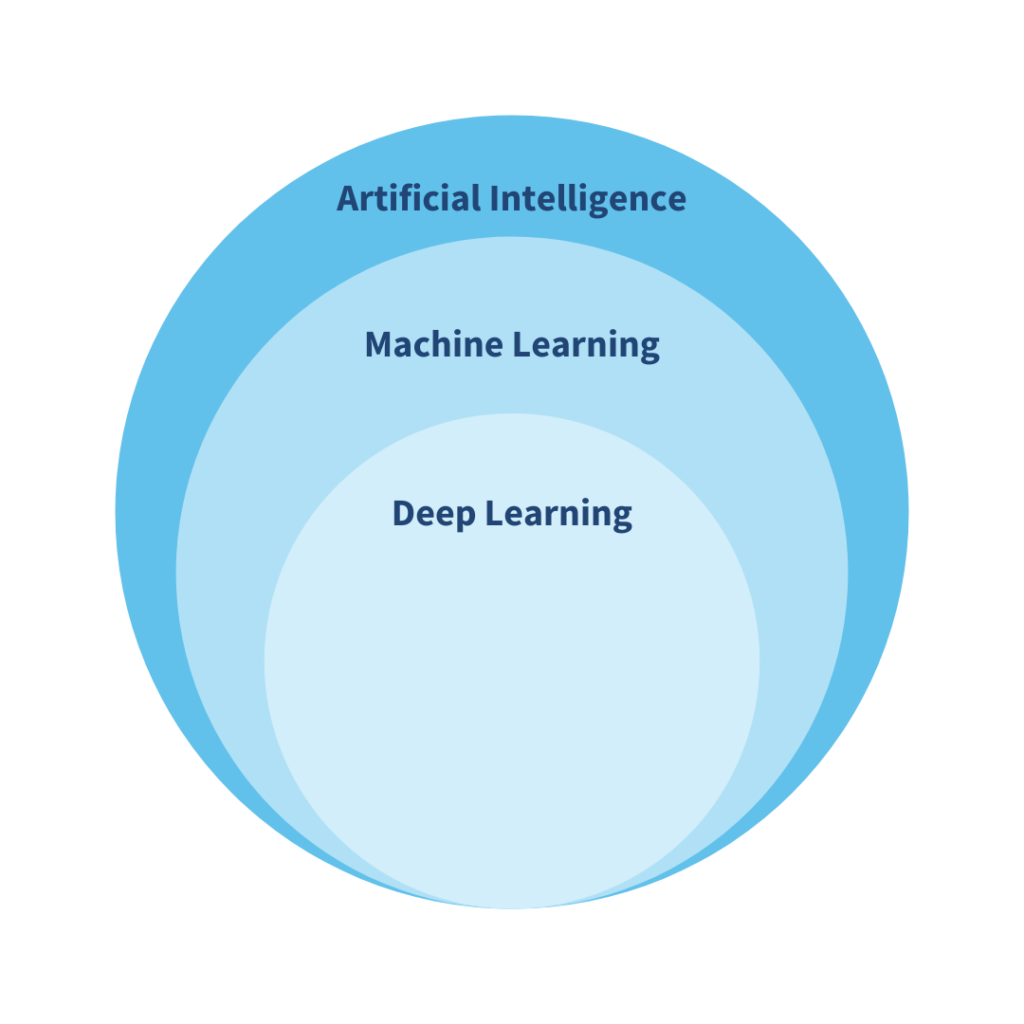
L’intelligence artificielle (IA) aide un ordinateur à imiter les humains grâce aux algorithmes d’apprentissage machine (ML). Le ML est une branche de l’IA qui permet à la machine de faire des prédictions ou des classifications en fonction des données sur lesquelles elle a été entraînée. L’apprentissage profond (DL) est une sous-branche du ML qui utilise des réseaux neuronaux, fonctionnant comme les neurones de notre cerveau, et qui peut prendre des décisions intelligentes de façon autonome.
Au cours des dernières décennies, de nombreuses applications de l’IA ont été développées dans différents domaines, comme la détection de fraude, la détection de tumeurs, la prévision météorologique, la prédiction boursière, la détection d’objets, la robotique, etc. D’autres sont encore en cours de développement, comme les voitures autonomes, qui continueront d’être perfectionnées dans les prochaines années. Les modèles d’IA existants fonctionnent très bien avec une bonne précision. Il est donc très important de choisir les bons algorithmes pour obtenir un modèle précis.
Le ML dispose d’une variété d’algorithmes adaptés aux petits ensembles de données et nécessitant moins de temps pour entraîner un modèle. En revanche, les algorithmes de DL, comme les RNN (réseaux neuronaux récurrents) ou les CNN (réseaux de neurones convolutionnels), conviennent aux grands ensembles de données et aux applications complexes, mais nécessitent beaucoup de temps pour l’entraînement. La performance d’un modèle ML/DL dépend de la taille et de la dimensionnalité de l’ensemble de données, de la capacité à gérer les valeurs aberrantes, de l’optimisation des hyperparamètres et de la vitesse de calcul. Il existe souvent une confusion voulant que les modèles de DL offrent toujours une meilleure précision que ceux de ML. Ce n’est pas toujours le cas, car la performance du modèle dépend de la taille et du type de données, et les réseaux neuronaux ont besoin d’un très grand volume de données pour s’entraîner efficacement. Si l’ensemble de données est petit, il est possible qu’un modèle DL ne donne pas de bons résultats.
Dans le secteur océanique, il existe plusieurs applications possibles de l’IA, comme la prédiction du poids des poissons, la classification et la détection de poissons, ainsi que la prévision météorologique. La prédiction du poids des poissons est un problème de régression qui peut être résolu avec des algorithmes comme la régression linéaire ou polynomiale. La détection et la classification de poissons sont des problèmes de classification; dans ce cas, l’ensemble de données sera constitué d’images et nécessitera un algorithme comme le CNN pour obtenir une meilleure précision. Pour des problèmes récurrents, on peut utiliser les RNN, par exemple pour la prévision météorologique à partir de données historiques. Les données océaniques peuvent être massives et les modèles de DL très complexes. Par conséquent, l’entraînement de ces modèles sur de grands ensembles de données exige une puissance de calcul considérable. L’infrastructure de calcul haute performance (HPC) de DeepSense offre une grande mémoire, plusieurs cœurs, des GPU haut de gamme et un vaste espace de stockage pour accélérer les calculs et ainsi améliorer grandement l’efficacité et la précision des applications réelles.
Pour en savoir plus sur le choix des bons algorithmes, vous pouvez visionner notre webinaire ici.