



Par : Mayank Anand *, Natasha Hynes, Amit Baroi, Alex Pottier, Kim Davies
Résumé
Dans le domaine des écosystèmes océaniques, le rôle vital du zooplancton dans le maintien de l’équilibre et la facilitation des processus essentiels de la Terre a suscité une attention considérable. Relever le défi complexe de reconnaître avec précision le zooplancton est essentiel pour les études et les mesures scientifiques. Cependant, l’identification manuelle du zooplancton, bien qu’indispensable, est freinée par sa nature laborieuse et exigeante en temps, principalement en raison de la nécessité d’une expertise spécialisée. L’émergence de l’apprentissage profond a ouvert une avenue transformatrice vers le progrès, misant sur ses performances impressionnantes dans diverses tâches de classification et de segmentation. Dans cette recherche, nous présentons une solution novatrice de vision par ordinateur conçue pour classifier des images en ombrographie de zooplanctons. Notre approche implique un ensemble de réseaux de neurones convolutionnels stratégiquement combinés afin d’atteindre un équilibre optimal entre la réduction des faux positifs et des faux négatifs. Cette fusion concertée a permis d’obtenir une précision d’inférence remarquable de 94,42 %. De plus, nous introduisons un modèle de segmentation d’images de type encodeur-décodeur, enrichi de couches de convolution et de déconvolution. Ce modèle excelle à générer des masques surpassant la fidélité des masques réels, ce qui met en évidence son potentiel pour une délimitation méticuleuse.
1. Introduction
1.1 Motivation
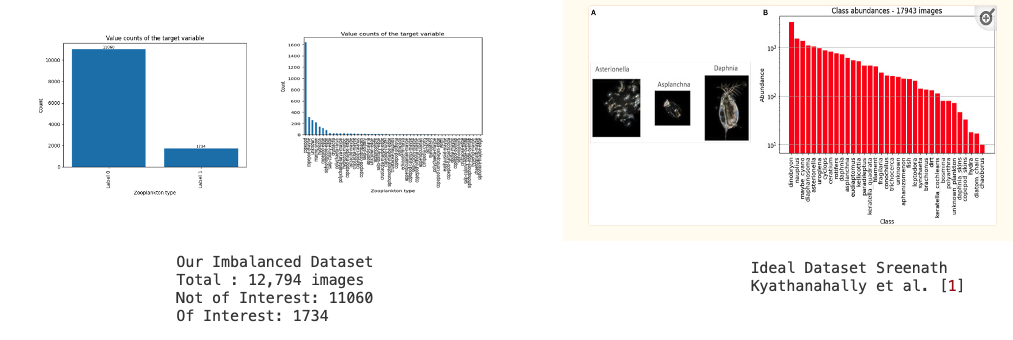
La force motrice derrière notre recherche découle de la tâche complexe et laborieuse d’identifier manuellement le zooplancton dans des images en ombrographie. Ce processus exige une expertise spécialisée pour discerner les images pertinentes, ce qui entraîne un investissement de temps considérable qui freine la progression des efforts de recherche parallèles. Reconnaissant ce problème comme un enjeu majeur, nous avons conçu notre étude afin de relever ces défis et de faire avancer le domaine. Bien que des recherches importantes aient été menées récemment, particulièrement dans l’étude du zooplancton lacustre, comme le travail de Sreenath Kyathanahally et al. [1], les difficultés sont amplifiées lorsqu’il s’agit de l’eau de mer de la baie de Fundy. Cet environnement présente un défi unique, car une proportion substantielle des images ne contient pas d’animaux identifiables. Par conséquent, cela mène à un jeu de données fortement déséquilibré, ce qui le distingue d’autres études où les ensembles de données sont plus uniformément distribués. Les réseaux de neurones convolutionnels, bien qu’ils connaissent un grand succès avec des jeux de données équilibrés, rencontrent des défis dans notre scénario. Pour illustrer cette disparité, considérez l’histogramme ci-dessous, qui montre la distribution des images contenant des animaux dans notre ensemble d’entraînement comparativement à d’autres études en eau douce.
1.2 Énoncé du problème
La recherche se concentre sur l’énoncé suivant : pour une image non recadrée donnée, nous visons à déterminer si l’image contient un animal. De plus, si un animal est détecté, notre objectif est de repérer son emplacement exact dans l’image. Pour ce faire, nous avons d’abord développé un classificateur binaire afin de filtrer et d’identifier les images pertinentes contenant des animaux. Par la suite, nous avons conçu un modèle de segmentation pour localiser avec précision l’animal dans les images sélectionnées.
2. Matériel et Méthodes
2.1 Analyse exploratoire des données et premières expériences
Notre ensemble de données, comprenant environ 41 860 images, offre une grande richesse d’informations. Parmi celles-ci, 12 794 images ont été méticuleusement annotées par des experts du Laboratoire des sciences biologiques de l’Université du Nouveau-Brunswick. Sur ces images annotées, 1 734 contiennent des animaux. Ci-dessous, à gauche, se trouvent les images que nous avons obtenues après découpage à partir des annotations. Nous avons créé une petite animation à partir d’un sous-ensemble d’images recadrées, comme illustré. À droite, nous présentons une animation similaire avec des images non recadrées.


Les annotations ne se limitent pas à identifier la présence d’animaux dans les images, elles fournissent aussi des informations précises sur leur emplacement. Ces informations sont soigneusement consignées dans un fichier CSV accompagnateur. Il est à noter que les annotations varient en forme, allant de contours polygonaux à des boîtes englobantes carrées, comme illustré dans les images ci-dessous. Ces variations ont posé des défis lors de la création de masques pour la segmentation par la suite.


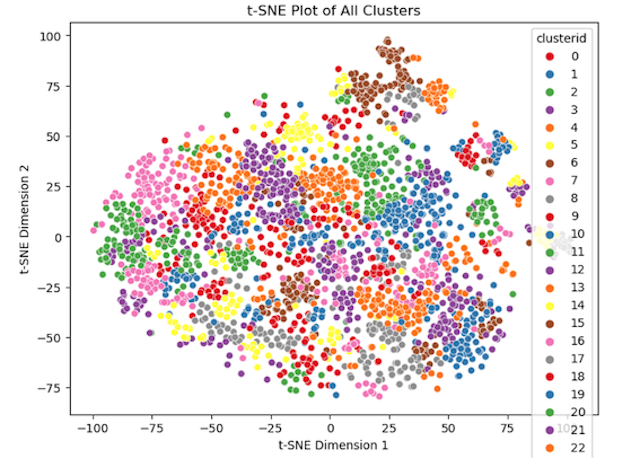
Nous avons entrepris d’explorer les deux voies de l’apprentissage profond : les approches non supervisées et supervisées. Nous avons commencé par utiliser une méthode d’apprentissage non supervisé. Nous avons conçu deux auto-encodeurs pour encoder deux types d’images dont nous disposions : les images non recadrées et les images recadrées. Ces dernières ont été générées à l’aide d’annotations du fichier CSV fourni. Après l’encodage, nous avons appliqué un regroupement EM aux vecteurs latents obtenus grâce à l’encodage de ces images. Nous avons ensuite généré des graphiques t-SNE pour les deux expériences. L’analyse des grappes a révélé une forte dispersion des images contenant des animaux, comme l’illustrent les graphiques t-SNE. Si nous avons obtenu des grappes significatives, l’approche a été inefficace pour les images non recadrées en raison d’une quantité importante de pixels noirs présents dans les images obtenues avec l’objectif de l’ombrographe. Cela a mené à des vecteurs latents peu informatifs, entraînant une forte similarité entre la plupart des vecteurs de l’espace vectoriel.


2.2 Préparation et prétraitement des données
En raison de la difficulté d’établir une frontière de décision claire entre les images qui nous intéressaient et celles qui ne l’étaient pas, nous avons décidé d’employer des techniques d’apprentissage supervisé, plus précisément des réseaux de neurones convolutifs profonds. Afin d’assurer la compatibilité avec nos modèles, nous avons standardisé la taille de toutes les images à 256 x 256. Cette dimension a été choisie grâce à l’ajustement d’hyperparamètres. Pour la tâche de segmentation, nous avons opté pour une taille d’image de 512 x 512. Ce choix permettait d’obtenir des résultats optimaux tout en respectant la mémoire GPU disponible, évitant ainsi les plantages de noyau dans nos notebooks AWS Sagemaker. Nous n’avons appliqué aucune transformation pour notre tâche de classification, mais nous avons normalisé nos images avec mean = [0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225]. Par contre, pour la tâche de segmentation, l’augmentation des données s’est révélée inestimable pour raffiner la précision de nos frontières de décision lors de la segmentation des animaux. Notre stratégie d’augmentation comprenait des retournements horizontaux aléatoires, des retournements verticaux aléatoires et des rotations aléatoires avec des angles variables allant jusqu’à 20 degrés. De plus, nous avons substantiellement enrichi notre ensemble de données, en générant des masques réels correspondants pour améliorer le processus de segmentation.

Pour notre tâche de segmentation, il était crucial d’avoir une référence, ou une vérité terrain, à laquelle comparer les prédictions de notre modèle. Pour ce faire, nous avons généré de véritables masques, dérivés d’annotations détaillées répertoriées dans le fichier « annotation.csv ». Ces annotations s’appliquaient à toutes les images mettant de l’avant des animaux. Ce processus de création de masques ne se résume pas à une simple conversion binaire, mais implique des étapes complexes pour s’assurer que les masques sont précis et représentatifs de la répartition et de la forme réelles des animaux sur les images. L’image ci-dessous offre une représentation visuelle illustrant le processus méticuleux de création de ces masques.

2.3 Entraînement, validation et test
Pour partitionner efficacement nos images, nous les avons séparées en ensembles distincts d’entraînement, de validation et de test. Nous avons de plus réservé un ensemble de 500 images pour un usage exclusif durant la phase de test, en les gardant entièrement séparées des ensembles d’entraînement et de validation. Les images restantes ont été divisées, avec 80 % destinées à l’ensemble d’entraînement et les 20 % restants à l’ensemble de validation. Pour la tâche de segmentation, une approche similaire a été utilisée. Nous avons alloué 80 % des données à l’entraînement, 10 % à la validation et les 10 % finaux aux tests. Dans la section des résultats, nous présentons diverses matrices de confusion relatives à la tâche de classification, en mettant l’accent sur l’ensemble de 500 images réservées pour le test. Afin d’évaluer l’efficacité de l’annotation humaine, nous avons fourni ce même ensemble d’images à des annotateurs humains et obtenu des matrices de confusion en comparant nos prédictions aux annotations réelles.
2.4 Architectures d’apprentissage profond
2.4.1 Classification binaire
Pour la classification binaire, nous avons conçu un réseau convolutionnel composé de trois couches convolutionnelles, chacune couplée à une fonction d’activation ReLU. Après chaque couche convolutionnelle, nous avons intégré un dropout et une opération de max-pooling, formant ensemble un bloc convolutionnel. Notre architecture est structurée avec trois de ces blocs, comme illustré dans la visualisation suivante. Après les opérations convolutionnelles, la conception inclut trois couches entièrement connectées, se terminant par une fonction sigmoïde qui prédit la probabilité qu’une image soit assignée à la classe étiquetée « 1 ». Pour renforcer la précision du modèle, nous avons incorporé un seuil apprenable. Ce seuil, adapté pour réduire les faux négatifs, est ajusté après chaque époque d’entraînement, en se basant sur les métriques de performance de l’ensemble de validation. Le seuil finement ajusté joue un rôle crucial dans la classification de l’image. Pour le processus d’optimisation, nous avons utilisé la fonction de perte Binary Cross-Entropy, avec l’objectif de minimiser sa valeur résultante.

2.4.2 Segmentation
Pour notre tâche de segmentation, nous avons entrepris une analyse approfondie et choisi d’utiliser l’architecture présentée dans la recherche de Ronneberger et al. [4]. Ce modèle a constamment démontré une performance supérieure dans les tâches de segmentation de bioimages. Étant donné que nos images contiennent de petits animaux distincts, cette architecture U-net a été jugée le choix le plus approprié.
Le modèle comprend trois composantes principales :
- Module Encodeur : Ce module contient une série de couches convolutionnelles, complétées par des opérations de MaxPooling. De plus, nous avons intégré des couches de normalisation par lot (Batch Normalization) et de Dropout dans chaque bloc convolutionnel afin d’améliorer respectivement la stabilité et la régularisation.
- Couches Bottleneck : Situées entre l’encodeur et le décodeur, elles se composent d’une paire de couches convolutionnelles et déconvolutionnelles.
- Module Décodeur : Le décodeur comporte une séquence de couches déconvolutionnelles, couplées de façon unique à des connexions de saut (skip connections) provenant de l’encodeur. Il est important de souligner que, bien que ces connexions de saut soient cruciales dans notre cas, elles ne sont pas typiquement intégrées dans les architectures autoencodeurs standards. Enfin, le modèle se termine par une couche de sortie composée de couches convolutionnelles. La sortie de cette couche est ensuite soumise à une perte Binary Cross Entropy, comparée au masque réel. Ces masques réels sont générés à partir des annotations fournies dans un fichier CSV accompagnateur. Ci-dessous, nous présentons plusieurs exemples de masques utilisés lors du calcul de la perte.


3. Expériences et Résultats
3.1 Classification binaire
3.1.1 Exécution préliminaire sans ajustement d’hyperparamètres
Lors de notre exécution préliminaire, nous avons utilisé l’optimiseur ADAM pour minimiser la perte Binary Cross Entropy. Le taux d’apprentissage a été fixé à 0,001 et une décroissance sur les paramètres apprenables a été définie à 1e-5. Cette décroissance agit comme une régularisation L2 des poids dans notre modèle. Nous avons fixé beta1 à 0,8 et beta2 à 0,999, avec un epsilon de 1e-8. Étant donné le déséquilibre important de notre ensemble de données, nous avons ajusté la fonction de perte pour pénaliser plus fortement lorsque le modèle prédisait incorrectement la classe minoritaire (étiquette « 1 »). Cette étiquette indique la présence d’un animal dans l’image. Selon la distribution de notre ensemble de données, nous avons déterminé un ratio de pénalisation de la perte : loss_ratio = label_counts[0] / label_counts[1] = [1,0000, 6,3882]. Pour assurer la stabilité pendant les phases initiales d’entraînement, nous avons intégré un réchauffement du taux d’apprentissage pour les 100 premières étapes, après quoi le taux a été maintenu constant à 0,001. Nous avons entraîné le modèle pendant 30 époques, et les résultats, présentés dans la matrice de confusion, sont détaillés dans la section suivante.
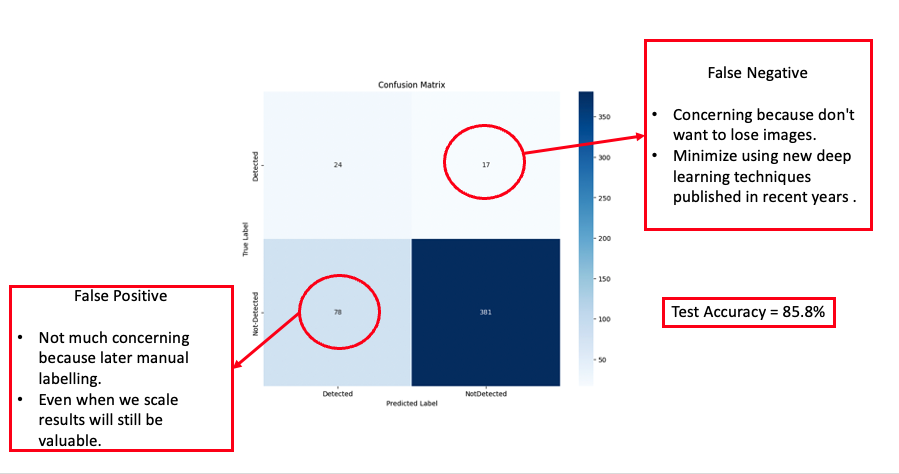
D’après nos premiers résultats, nous avons obtenu une précision de 85,80 %. Cependant, nous avons observé un nombre important de faux positifs et de faux négatifs. La principale préoccupation concernait les faux négatifs, puisque perdre des images dans un ensemble déjà déséquilibré pouvait être néfaste. Mal classifier et ensuite omettre des images pouvait réduire encore davantage le nombre limité d’images confirmant la présence d’animaux. Par conséquent, nos expériences subséquentes visaient à explorer des techniques avancées d’apprentissage profond capables de réduire efficacement à la fois les erreurs de type I et de type II dans nos prédictions.
3.1.2 Ajustement d’hyperparamètres à l’aide d’une grille
Nous avons entrepris un ajustement d’hyperparamètres en utilisant une grille, en nous concentrant sur les paramètres suivants :
- Modèles : Par l’expérimentation avec diverses architectures, il a été noté qu’augmenter la profondeur de notre modèle entraînait du surapprentissage (overfitting). Cela nuisait à la performance du modèle en validation.
- Taux d’apprentissage : Un éventail de taux d’apprentissage (0.1, 0.01, 0.001 et 0.0001) a été évalué. L’analyse a indiqué qu’un taux de 0.001 donnait le meilleur résultat.
- Décroissance de poids : Nous avons évalué plusieurs valeurs de weight decay, incluant 1e-3, 1e-4, 1e-5 et 1e-7. La performance optimale a été observée avec une valeur de 1e-7.
- Dropout : Pour contrer le surapprentissage, nous avons expérimenté différents taux de dropout (0.05, 0.1, 0.2, 0.3 et 0.4). À travers ces tests, un taux de 0.2 s’est avéré le plus efficace.
- Taille de lot (Batch Size) : Nous avons évalué l’effet de différentes tailles de lot sur la performance du modèle, spécifiquement 16, 32 et 64. La taille de lot de 16 a produit les meilleurs résultats.
Dans notre exploration des techniques contemporaines d’apprentissage profond, nous avons intégré l’optimiseur RAdam [2], tel que proposé par Liu et al. dans leur recherche [2]. Cela a remplacé notre choix initial, l’optimiseur Adam. De plus, nous avons mis en œuvre la technique de l’optimiseur Lookahead, en fixant k à 10, alpha à 0.5 et en sélectionnant RAdam [2] comme optimiseur de base, suivant la méthodologie décrite par Zhang et al. [3] dans leur étude. L’intégration de ces techniques a considérablement amélioré nos résultats, qui sont détaillés dans les sections suivantes.
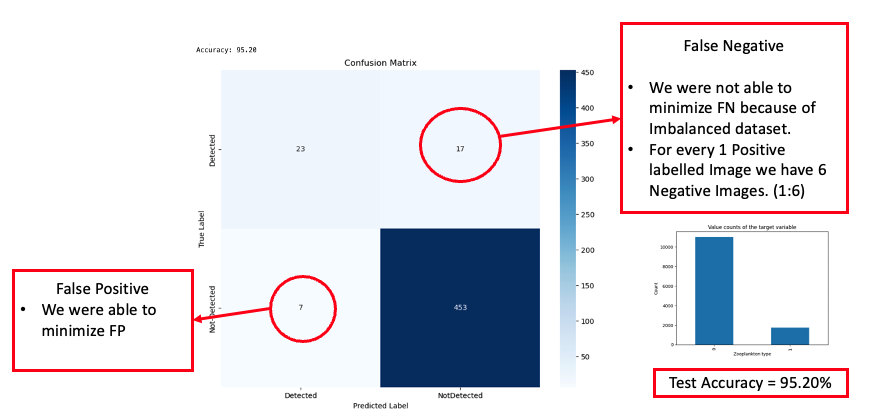
Dans la visualisation présentée ci-dessus, nous avons observé une amélioration significative de la précision d’inférence, atteignant 95,20 %. Bien qu’il y ait eu une réduction marquée du nombre de faux positifs, la présence de faux négatifs demeurait préoccupante.
D’après les résultats, il est évident que les innombrables heures consacrées à l’optimisation des hyperparamètres, combinées à l’intégration des avancées récentes dans le domaine de l’apprentissage profond, ont donné lieu à des résultats améliorés. La précision du modèle a bondi, atteignant un score remarquable de 95,20 %. Bien que nous ayons réussi à réduire substantiellement le nombre de faux positifs, les faux négatifs continuaient à poser un défi important. Après analyse, nous avons soupçonné que la raison principale pouvait être la nature déséquilibrée de notre ensemble de données. Le modèle avait une exposition limitée à la classe minoritaire, étiquetée « 1 », qui représente les images contenant des animaux. Ce manque de représentation est probablement un facteur important expliquant notre incapacité à réduire efficacement les faux négatifs.
3.1.3 Sous-échantillonnage de la classe majoritaire
À la lumière de nos observations concernant la performance du modèle avec un ensemble de données déséquilibré, nous avons décidé d’essayer une approche différente. Plus précisément, nous avons sous-échantillonné notre classe majoritaire, étiquetée « 0 », représentant les images sans animaux. Ce faisant, notre objectif était d’égaler le nombre de ces images à celui de la classe minoritaire, étiquetée « 1 », indiquant la présence d’animaux. Cet ajustement a considérablement réduit le nombre total d’images disponibles pour l’entraînement, diminuant par conséquent le nombre total d’étapes d’apprentissage, puisque le modèle disposait désormais de moins d’exemples à traiter. Néanmoins, nous avons choisi de conserver les hyperparamètres de notre expérience précédente, étant donné leur efficacité démontrée. Les résultats de cette expérience sont discutés dans les sections qui suivent.
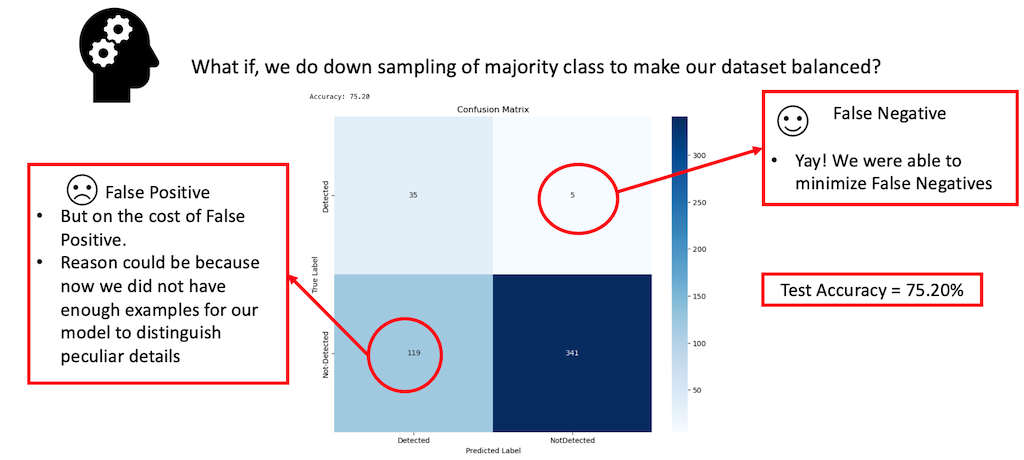
Dans la visualisation présentée ci-dessus, nous avons observé une amélioration significative dans la réduction des faux négatifs après l’équilibrage de notre ensemble de données, mais au prix de la précision globale du modèle, qui a diminué à 75,20 %.
D’après nos résultats, il est devenu clair que le sous-échantillonnage de l’ensemble de données a permis de régler efficacement le problème des faux négatifs. Cependant, cela s’est fait au détriment de la précision globale du modèle. La baisse de précision peut être attribuée au fait que le sous-échantillonnage de la classe majoritaire nous a laissé avec beaucoup moins d’exemples pour l’entraînement, ce qui a affecté la performance du modèle. De plus, nous avons expérimenté un suréchantillonnage de la classe minoritaire en générant de nouveaux exemples d’images avec des animaux. Cela impliquait d’appliquer des transformations similaires à celles utilisées pour la tâche de segmentation. Toutefois, cette stratégie n’a pas produit les améliorations escomptées dans nos résultats.
3.1.4 L’ensemble de modèles
Dans notre quête d’un équilibre idéal entre la réduction des faux négatifs et des faux positifs, sans sacrifier la précision globale du modèle, nous avons conçu une nouvelle approche par ensemble. Cette approche combinait les forces des modèles que nous avions examinés dans nos expériences précédentes. L’idée centrale était de fusionner la haute précision d’un modèle avec la diminution des faux négatifs de l’autre, en prenant une moyenne pondérée de leurs prédictions. Il est important de noter que déterminer la pondération exacte est devenu un nouveau défi d’hyperparamétrage. Après plusieurs itérations, nous avons identifié un mélange optimal qui offrait un équilibre louable entre les erreurs de type I et de type II, tout en maintenant la haute précision du modèle. Cette méthode innovante par ensemble met en lumière les avantages de combiner différents modèles en apprentissage automatique. En tirant parti des forces distinctes de chaque modèle, nous avons surmonté les défis précédents, soulignant le principe selon lequel les approches collaboratives mènent souvent à de meilleurs résultats dans les expériences d’apprentissage profond.
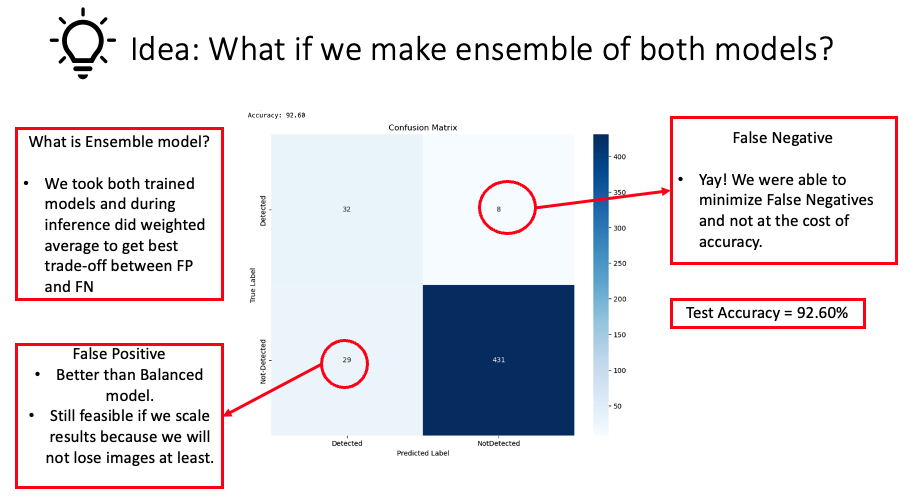
D’après la visualisation présentée ci-dessus, nous avons observé une réduction significative des faux négatifs après avoir utilisé un ensemble des deux modèles précédents, avec seulement un impact minimal sur la précision (92,60 %).
D’après la matrice de confusion présentée, il est évident que la méthode par ensemble est l’approche optimale pour ce problème. En utilisant cette méthode, nous avons réduit de façon significative les faux négatifs, avec seulement un compromis minime sur la précision. De plus, ces résultats non seulement valident, mais mettent aussi en valeur la robustesse de notre modèle dans la classification des images. Les niveaux impressionnants de précision, combinés à la réduction des erreurs de type II, soulignent la fiabilité et l’efficacité du modèle. Cet accomplissement, vu dans une perspective plus large, renforce l’idée d’adopter des méthodes par ensemble dans des défis similaires, reflétant leur force intrinsèque à tirer parti des meilleurs attributs de chaque modèle pour produire un résultat global amélioré.
3.2 Segmentation
Pour notre tâche de segmentation, nous avons utilisé l’optimiseur RAdam [2] avec un taux d’apprentissage de 0,001 afin d’optimiser la perte Binary Cross Entropy. Le modèle a été entraîné sur 100 époques. Comme démontré dans les images ci-dessous, les masques obtenus sur l’ensemble de validation ont surpassé la qualité des masques réels. Fait notable, notre modèle pouvait détecter et segmenter plusieurs animaux dans une seule image.

Cette image présente les masques de sortie produits par notre modèle sur l’ensemble de validation. Comme on peut le constater, la qualité et la précision de la segmentation surpassent celles des masques réels. Plusieurs animaux de l’image sont clairement segmentés, ce qui témoigne de la performance du modèle.
Il est intéressant de noter que, dans nos annotations, il y a eu quelques cas où même nos annotateurs humains n’ont pas pu déterminer avec certitude la présence d’animaux dans certaines images. Cependant, lorsque nous avons examiné les résultats de notre modèle, nous avons été très impressionnés. Le modèle a réussi à identifier des animaux dans ces images complexes, où même nos yeux doutaient, comme le montre l’image ci-dessous, dont le nom est surligné en rouge.

Ici, nous avons une image difficile où même nos annotateurs humains hésitaient quant à la présence d’animaux. De façon remarquable, notre modèle a relevé le défi, identifiant et segmentant avec assurance des animaux potentiels dans ces zones d’ambiguïté.
3.3 ZooSegNet : Combinaison de la classification et de la segmentation
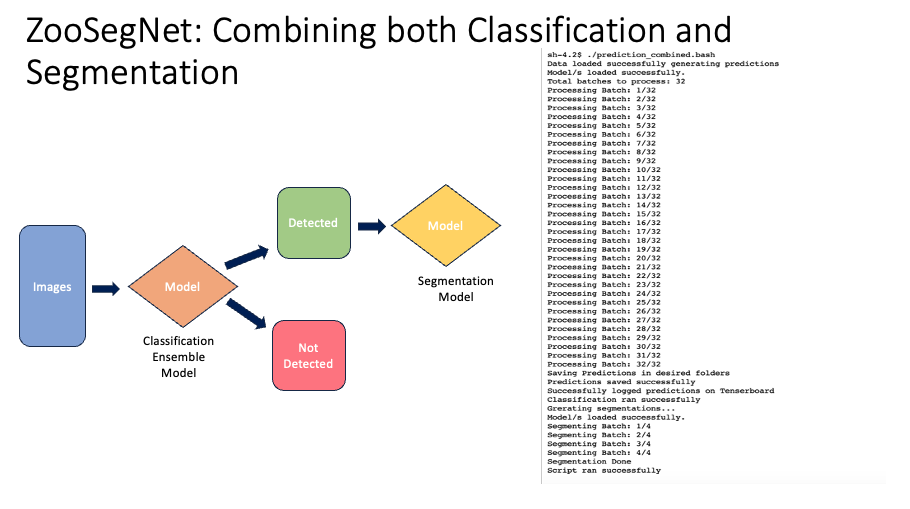
Nous avons introduit ZooSegNet, une intégration fluide des modèles de classification et de segmentation. L’objectif principal de cette approche était d’abord de discerner les images contenant des animaux, puis de localiser précisément ces animaux dans les images détectées.
3.3.1 Méthodologie
À la réception des images en entrée, un script Python a été utilisé. Ce script classait d’abord les images, les déplaçant vers les dossiers « Detected » ou « NotDetected » selon leur contenu. Après la classification, le modèle de segmentation était appliqué uniquement aux images du dossier « Detected ».
3.3.2 Résultats qualitatifs
Segmentation d’un seul animal : L’image la plus à gauche illustre la capacité de notre modèle à segmenter avec précision un seul animal. Le masque superposé met en évidence l’emplacement exact de l’animal dans l’image originale.
Segmentation de plusieurs animaux : L’image suivante, à droite, démontre comment notre modèle gère efficacement des scènes comportant plusieurs animaux, en s’assurant que chacun soit clairement segmenté sans en manquer aucun.


3.3.3 Résultats quantitatifs
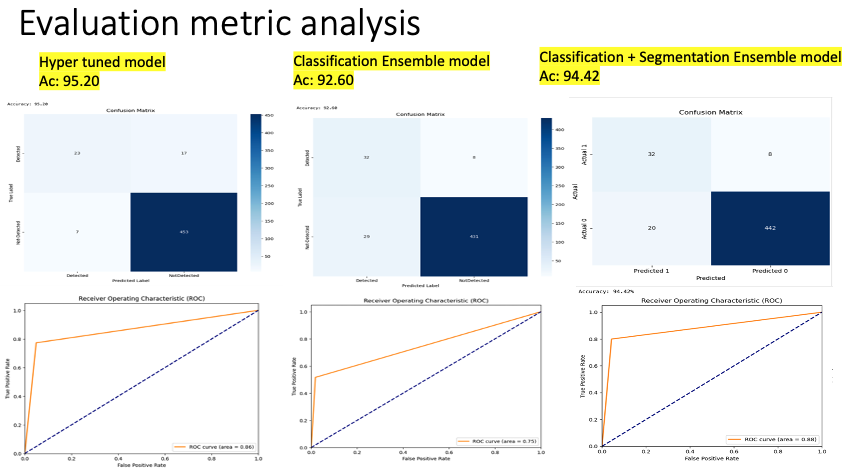
Dans une exploration plus approfondie de notre ensemble de test, une tendance intéressante est apparue. Certaines images qui ont induit en erreur notre modèle de classification n’ont pas trompé notre modèle de segmentation. Fait intéressant, les masques produits pour ces images spécifiques étaient majoritairement noirs. Une analyse plus poussée a révélé que ces images correspondaient aux faux positifs ignorés par notre modèle de classification. Cette constatation met en évidence l’efficacité de notre technique par ensemble, « ZooSegNet ». En combinant les deux modèles, l’ensemble améliore la fiabilité du réseau, le renforçant contre de potentielles erreurs de classification. L’efficacité de ZooSegNet est démontrée par ses métriques de performance impressionnantes. Notamment, notre ensemble a surpassé le modèle de classification autonome, augmentant la précision de 2 % pour atteindre un résultat remarquable de 94,42 % sur l’ensemble d’inférence. Les sections suivantes compareront les mesures d’évaluation et illustreront les résultats à l’aide de la courbe ROC associée, mettant en évidence la performance et la fiabilité accrues de notre stratégie combinée.

Ce GIF animé comprend une séquence de neuf images illustrant les zones où notre ensemble ZooSegNet a fait preuve d’une précision remarquable. Chaque image présente des masques noirs, soulignant les cas où le modèle de classification a mal évalué, mais où l’approche de segmentation a judicieusement corrigé ces inexactitudes. Ces résultats visuels soulignent la force de l’ensemble : il fournit un cadre de détection plus complet, identifiant et corrigeant avec succès les erreurs occasionnelles du modèle de classification.
4. Code source et reproductibilité
Notre script Python et notre code source sont disponibles sur GitHub au lien suivant. Cliquez ici.
5. Conclusion
Explorer l’immense richesse des données océaniques, en particulier le mystérieux zooplancton, a toujours été une tâche redoutable. Cela exigeait une grande détermination, des connaissances spécialisées et beaucoup de temps. Néanmoins, cette recherche a mis en lumière le rôle puissant de l’apprentissage profond comme allié dans cette exploration. Alors que nos premières tentatives ont été confrontées à des obstacles tels que les faux négatifs et les problèmes posés par des ensembles de données déséquilibrés, la persévérance demeure un principe fondamental en science. En innovant continuellement, nous avons non seulement réduit ces erreurs, mais aussi créé une technique révolutionnaire par ensemble qui combinait les avantages de plusieurs modèles. Cet effort a permis d’atteindre une précision impressionnante de 94,42 %.
Cependant, le véritable succès ne réside pas seulement dans les statistiques. L’accomplissement authentique est l’impact pratique de notre travail. Le processus autrefois ardu de catégoriser et de localiser le zooplancton dans les images en ombrographie est désormais beaucoup plus efficace. De plus, notre système, ZooSegNet, avec son double rôle de classification et de segmentation, démontre le potentiel des méthodes combinées pour pallier les limites des modèles autonomes. En conclusion, réfléchir à notre parcours met en évidence que la portée de cette recherche va bien au-delà de ses résultats directs. Elle illustre la valeur de la ténacité, du travail d’équipe et de la créativité dans le domaine scientifique. L’océan vaste et mystérieux reste un défi pour plusieurs, mais avec des innovations comme la nôtre, nous nous rapprochons de la découverte de ses secrets.
6. Remerciements
La caméra d’ombrographie a été développée par Williamson and Associates Technologies (Seattle, WA) et prêtée par Christian Reiss du NOAA Southwest Fisheries Science Centre pour ce projet. Les images ont été recueillies grâce au financement et au soutien logistique de l’Ocean Tracking Network, de la Tides Foundation, de Pêches et Océans Canada – Fonds de la nature du Canada pour les espèces aquatiques en péril, ainsi que de la Fédération canadienne de la faune. La recherche a été réalisée en collaboration entre DeepSense et le Davies Lab de l’Université du Nouveau-Brunswick. Natasha Hynes et Emma Chaumont, du Davies Lab, ont annoté les images pour le projet.
7. Références
Kyathanahally, S. P., Hardeman, T., Merz, E., Bulas, T., Reyes, M., Isles, P. D. F., Pomati, F., & Baity‐Jesi, M. (2021b). Deep learning classification of Lake Zooplankton. Frontiers in Microbiology, 12. https://doi.org/10.3389/fmicb.2021.746297
Liu, L. (2020, April 1). On the Variance of the Adaptive Learning Rate and Beyond. https://iclr.cc/virtual_2020/poster_rkgz2aEKDr.html
Ronneberger, O., Fischer, P., & Brox, T. (2015). U-NET: Convolutional Networks for Biomedical Image Segmentation. In Lecture Notes in Computer Science (pp. 234–241). https://doi.org/10.1007/978-3-319-24574-4_28
Zhang, M. R., Lucas, J., Hinton, G., & Ba, J. (n.d.). Lookahead optimizer: K steps forward, 1 step back. Department of Computer Science, University of Toronto, Vector Institute. https://www.cs.toronto.edu/~hinton/absps/lookahead.pdf